GLM OCR 是什么
GLM OCR 是一款由人工智能驱动的免费文字识别工具,专门用于从图片、截图、扫描件和PDF文件中提取文字信息。它基于0.9B参数的轻量化AI模型,不仅能够识别印刷体,还能准确处理手写汉字、印章文字、复杂表格和数学公式。
在国内,无论是学生扫描教材、会计整理发票、还是档案员数字化历史文献,都离不开OCR工具。而GLM OCR 的最大价值在于:它完全免费,且对中文场景做了深度优化。无论是竖排古籍、手写批注,还是带有红章的合同,GLM OCR 都能以极高的准确率将图像转化为可编辑、可搜索的文本。
GLM OCR 的核心功能
GLM OCR 不是简单的“图片转文字”工具,它是一套完整的文档智能处理方案:
- 图片转文字:上传手机拍的课件、微信截图、扫描PDF,GLM OCR 能提取其中的全部文字内容。支持中英文混排、标点符号、代码片段和特殊字符,识别准确率可达99.9%。
- 表格识别与提取:传统OCR把表格识别成一堆散乱的文字,而GLM OCR 能理解表格结构——哪些是表头、哪些是数据行,输出后可直接粘贴到Excel中,无需二次整理。
- 公式识别成LaTeX:理工科学生和科研人员的福音。GLM OCR 可将复杂的数学公式(积分、矩阵、求和符号)直接转换为LaTeX代码,插入论文或笔记中。
- 手写文字识别:无论是课堂笔记、会议记录,还是老一辈的手写信件,GLM OCR 都能有效识别,准确率领先于市面上多数免费工具。
- 批量处理能力:单页处理速度约1.86页/秒,支持一次性上传多份文件,适合图书馆数字化、企业纸质档案电子化等场景。
- 多格式导出:支持纯文本、Markdown、LaTeX、JSON四种导出格式,满足普通用户、内容创作者、开发者的不同需求。
GLM OCR 的使用场景
场景一:大学生备考与写论文
小王在准备期末考试,手头有几十页师兄留下的纸质笔记和打印的文献。他用手机拍下照片,上传到GLM OCR,几分钟内就得到了一份可全文搜索的电子文档。论文写作时遇到一篇带复杂公式的英文论文,截图后用GLM OCR 转成LaTeX,直接复制进Overleaf,省去了手敲公式的麻烦。
场景二:行政财务人员处理票据
李姐每个月要整理数百张差旅发票和报销单。以前她需要一张张核对、手动录入Excel。现在她直接用GLM OCR 识别发票上的公司名、金额、日期,工具自动输出结构化的JSON数据,导入财务系统,效率提升了三倍以上。
场景三:开发者构建文档识别应用
某创业公司正在开发一款“拍名片自动建档”的小程序。他们在后端集成了GLM OCR 的本地部署版本,用户拍照上传名片,系统自动识别姓名、公司、职位、电话,无需支付第三方OCR的按次费用。
场景四:档案管理员数字化历史资料
某地方图书馆需要将上世纪五六十年代的油印报纸数字化。这些报纸字迹模糊、排版混乱,普通OCR几乎完全失效。GLM OCR 凭借其强大的上下文理解能力,成功提取出大量可检索文本,大大减轻了人工录入的负担。
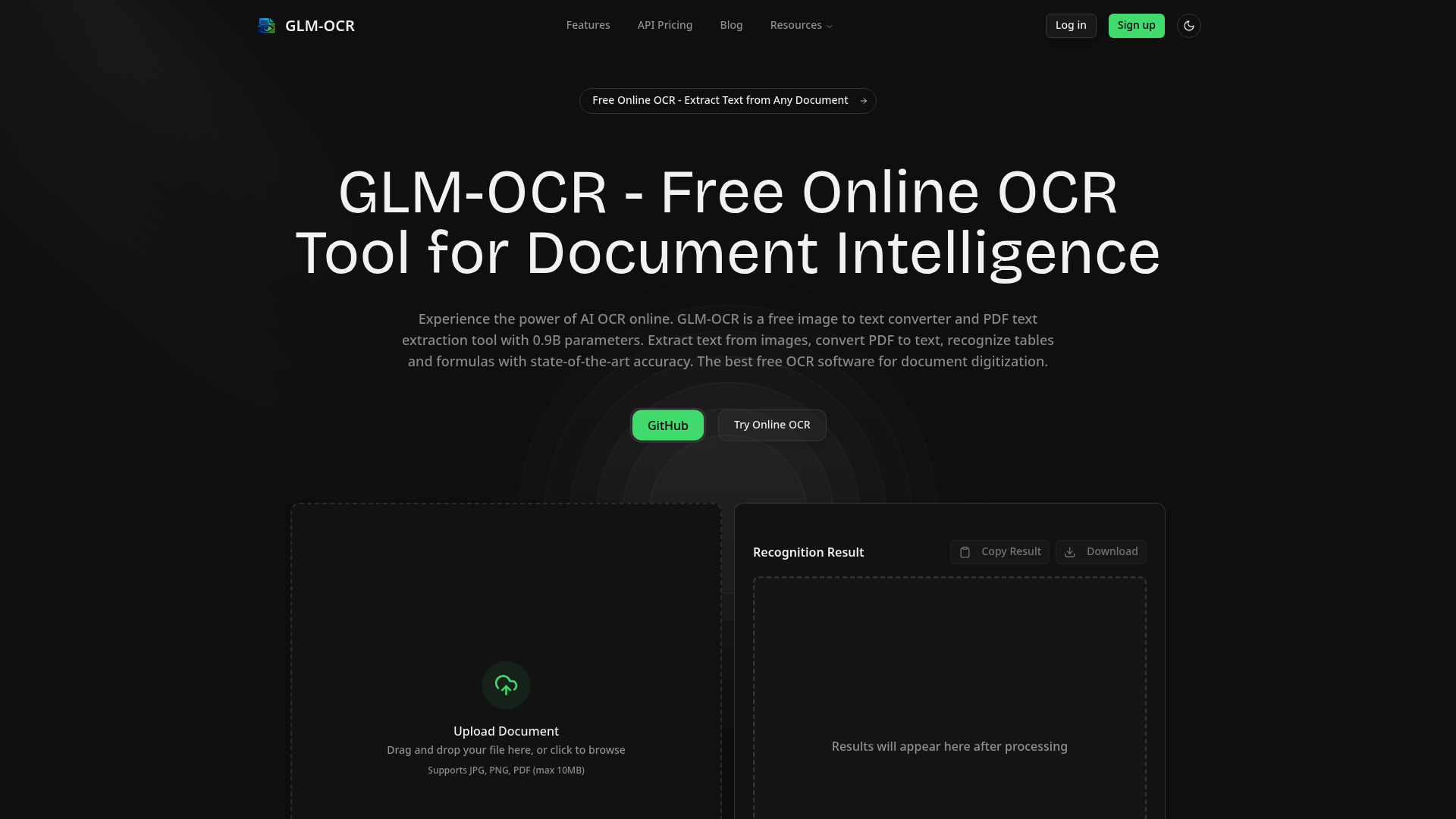
如何使用 GLM OCR
使用GLM OCR 不需要注册账号,也无需任何技术背景。整个流程三步即可完成:
- 访问官网:在浏览器中打开GLM OCR 在线工具页面。
- 上传文件:将图片(JPG、PNG)或PDF文件拖拽至上传区域,单文件大小不超过10MB。支持批量上传。
- 等待识别:点击“开始处理”,AI模型会自动分析图像中的文字、表格、公式。通常几秒钟内即可完成。
- 获取结果:右侧结果面板会直接显示识别出的文本。您可以一键复制,或选择纯文本、Markdown、LaTeX、JSON格式下载。
如果您是开发者或企业用户,GLM OCR 还提供了多种部署方式:通过Docker一键部署私有化服务;通过Ollama在本地运行;或调用云端API,每百万token仅需0.99美元。
GLM OCR 的优势
中文识别能力行业领先
市面上很多OCR工具由国外团队开发,对中文支持不够理想,尤其生僻字、手写汉字、竖排文字经常出错。GLM OCR 的底层模型在中文语料上做了充分训练,对汉字结构、笔画、上下文的理解更精准。
完全免费,无任何套路
绝大多数OCR工具要么限制每月免费次数,要么输出结果带水印,要么需要订阅会员。GLM OCR 的在线版完全免费、不限次数、无需登录、无水印,真正做到了“打开即用”。
表格与公式识别是杀手锏
对普通用户来说,识别一段连续文本并不难。真正的痛点是表格——传统OCR往往把一行表格识别成七八行乱码。GLM OCR 能智能还原表格结构,保留行列对应关系;公式识别精度达到96.5%,媲美商业软件。
部署灵活,保护数据隐私
对于涉及敏感信息(合同、身份证、病历)的文件,用户可以选择本地部署GLM OCR,所有处理都在内网完成,数据永不外传。开源免费的特性让企业无需担心授权风险。
轻量且高速
模型参数仅0.9B,远小于GPT-4等通用大模型,但在OCR专项任务上表现优异,处理速度快、硬件门槛低,普通CPU也能流畅运行。
GLM OCR 的定价模式
GLM OCR 采用“在线版完全免费 + 云端API按量付费 + 本地部署永久免费”的三层模式。
- 在线工具:永久免费。用户无需注册,不限识别次数,无水印,无功能阉割。适合个人用户、学生、小团队日常使用。
- 云端API:对于需要自动化、大规模调用的企业客户,GLM OCR 提供API接口,定价为每百万token 0.99美元。按实际消耗计费,无最低消费,无月度订阅费。
- 本地部署:GLM OCR 基于Apache 2.0开源协议发布,企业可在GitHub、Hugging Face、Ollama等平台免费下载模型,自行部署至内部服务器或云端虚拟机,无任何授权费用。
这种定价策略让GLM OCR 既服务了公益性质的个人用户,也满足了商业客户对成本控制和数据安全的要求。
关于GLM OCR 的常见问题
GLM OCR 支持哪些文件格式?
支持JPG、PNG和PDF格式,单文件大小上限为10MB。
识别结果可以导出为Excel吗?
目前支持直接导出为JSON格式,可通过Excel的“获取数据”功能轻松导入。纯文本格式下,表格会以Tab键分隔,直接粘贴也可使用。
识别手写中文准确率如何?
对于清晰、规范的手写汉字,GLM OCR 识别准确率在95%以上;对于连笔严重、潦草或涂改较多的手写内容,建议尽量上传清晰的原件。
GLM OCR 会保存我的文件吗?
在线版仅在上传处理期间暂存文件,处理完成后会自动从服务器清除。如对数据隐私有严格要求,建议使用本地部署版本。
有手机App吗?
目前GLM OCR 主要通过网页端使用,移动端浏览器体验良好。开发者可以基于开源的GLM OCR 自行封装移动应用。
识别繁体中文和古籍效果如何?
GLM OCR 对繁体中文有良好支持,并可识别部分竖排古籍。对于年代久远、字迹残缺的文献,建议配合图像预处理工具(如提高对比度)以获得更佳效果。
企业如何购买API额度?
GLM OCR 提供按量付费的API服务,无需预购套餐,用多少扣多少。具体开通方式请参考官网开发者文档。