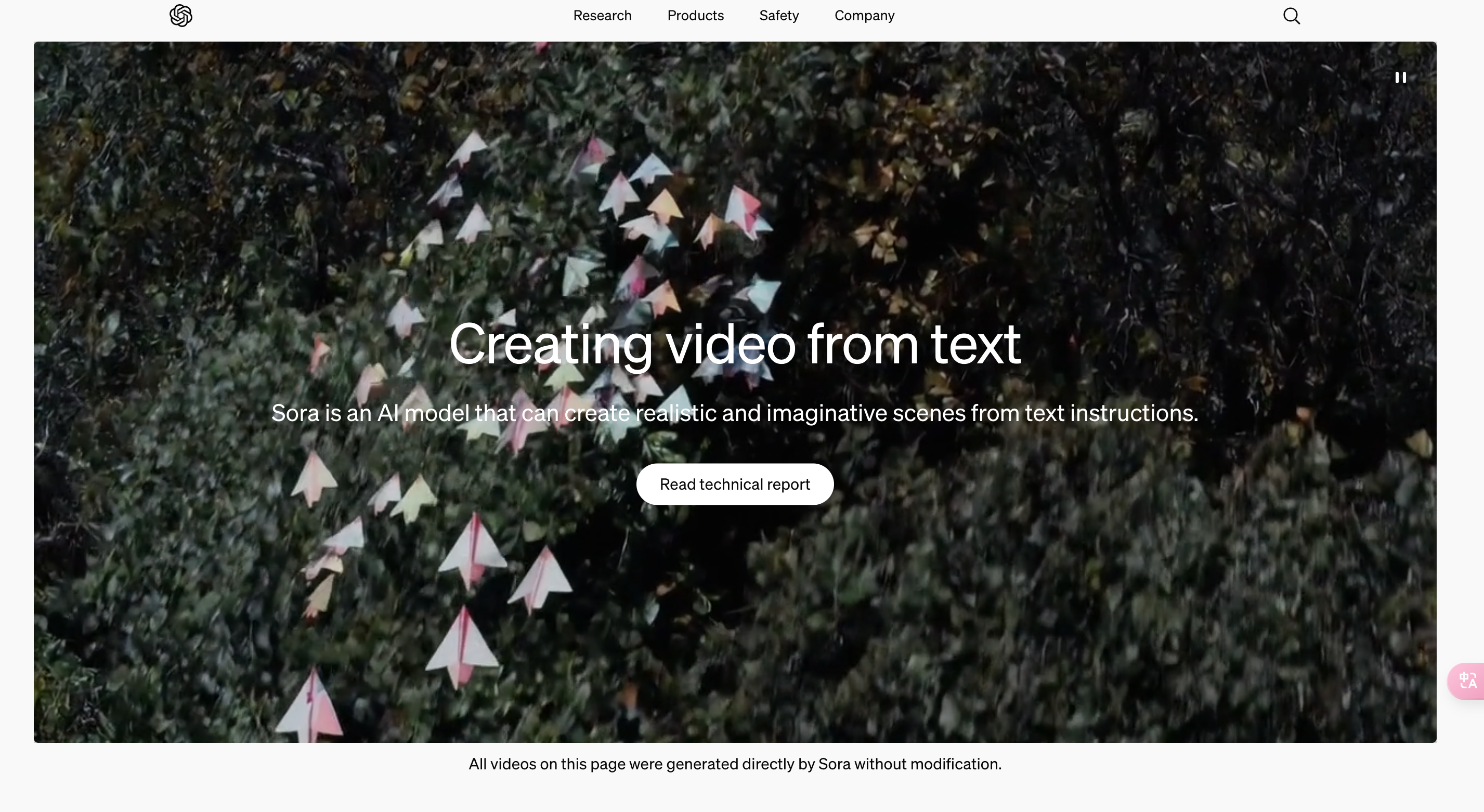
Sora AI 介绍
Sora是OpenAI于2023年2月发布的一款文本到视频生成模型。它能够根据描述性提示生成长达一分钟的视频,同时保持视觉品质并遵循用户提示。视频可以包含多个角色、特定类型的运动,以及主题和背景的准确细节。Sora旨在教人工智能理解和模拟运动中的物理世界,并训练其帮助人们解决需要现实世界互动的问题,因此被称作‘世界模拟器’。
Sora AI 功能
Sora的功能包括长视频生成、多机位、多角色、多分辨率和任意宽高比尺寸支持、高级语言理解能力、图片+提示=视频、视频时间扩展、无缝无限循环视频、视频到视频编辑、连接视频、高分辨率图像生成、3D一致性、远程相干性和物体持久性、与世界互动以及模拟数字世界等。
主要特点
- 长视频生成:能生成长达一分钟的高清视频,适合多种创作需求。
- 多机位与多角色:支持多角度和多角色场景,增加视频的丰富性和多样性。
- 高级语言理解:精确理解文本指令,生成高质量的视频内容。
- 图像+提示=视频:基于图片和文本提示生成视频,提供更多创作可能性。
优点
- 高准确性和多样性,能生成多种场景和人物的视频内容。
- 强大的语言理解能力,精确转化文本描述为视频。
- 多模态输入适配性,支持图像和视频编辑任务。
- 快速迭代优化,提高内容生成效率。
- 深层语义理解和创作,生成生动、真实的视频内容。
- 广泛的应用前景,如电影制作、游戏开发、新闻报道等。
缺点
- 可能存在技术局限性,如视频生成的真实性和复杂性。
- 对于某些特定场景或指令的理解和表现可能有限。
总结
Sora AI作为一款先进的文本到视频生成模型,不仅提供了丰富的功能和创作可能性,而且在多个领域有广泛的应用前景。尽管存在一些局限性,但其创新性和实用性使其成为未来影像创作的重要工具。